UNLOCK – Benchmarking Projects
The UNLOCK call was launched by the Helmholtz Association to promote benchmarking as a foundation for trustworthy and reproducible AI in science. Coordinated within the Helmholtz Information and Data Science Framework, UNLOCK supports the development of high-quality, open, and multimodal benchmarking datasets across domains such as health, climate, energy, and materials science. The selected projects initiate a Helmholtz-wide effort to establish AI benchmarking as a cornerstone of comparable and trustworthy AI, laying the foundation for future initiatives that will further expand this field across the Association. These projects lay the groundwork for a Helmholtz-wide AI benchmarking ecosystem.
The initiative connects domain scientists and AI experts to establish shared standards and reproducible pipelines for AI benchmarking. They benefit from close collaboration with Helmholtz AI, Helmholtz Imaging, HIFIS and HMC, and contribute to building a Helmholtz-wide community of practice for AI benchmarking.
Each project receives funding from the Helmholtz Initiative and Networking Fund and will publish its datasets openly to foster collaboration and advance AI-driven scientific discovery.
UNLOCK – Benchmarking Projects – ongoing
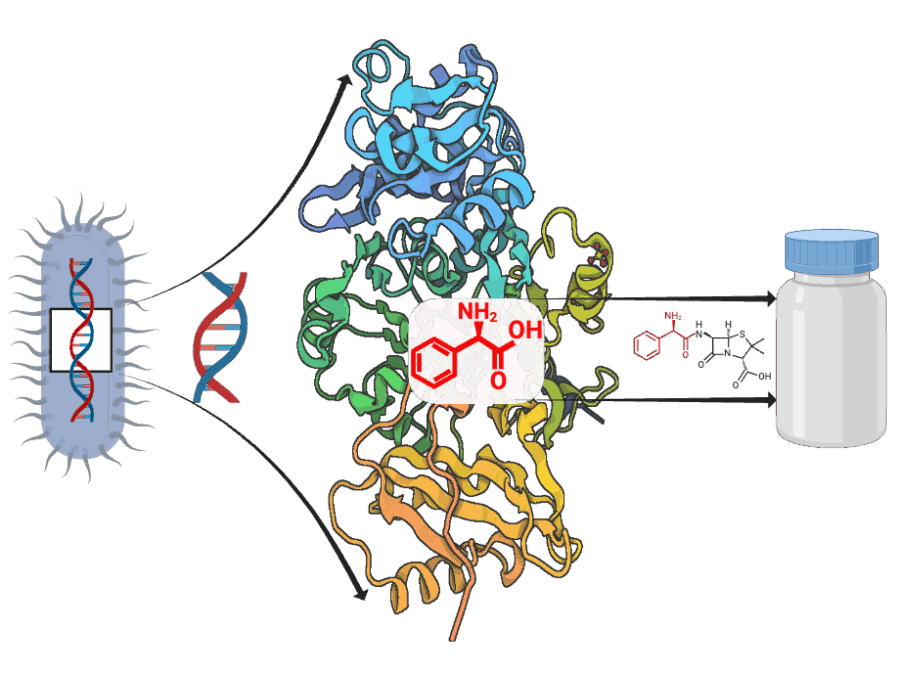
ADD-ON: Adenylation Domain Database and Online Benchmarking Platform
ADD-ON addresses the lack of reliable data for predicting how microbial enzymes assemble peptide-based natural products. By enabling accurate AI-driven structure prediction, it accelerates the discovery of new bioactive compounds and ultimately supports efforts to combat antimicrobial resistance.

AIMBIS – Artificial Intelligence for Microscopic Biodiversity Screening
Manual microscopic biodiversity monitoring is time-consuming and requires expert knowledge, limiting the potential for biodiversity monitoring, hence to recognize the impacts of climate and environmental change on crucial ecosystem functions.
AMOEBE: lArge-scale Multi-mOdal Microbial livE-cell imaging BEnchmark
Building a large-scale, FAIR benchmark for AI-driven analysis of microbial communities using time-lapse microscopy to advance understanding of microbial dynamics, ecosystem stability, and their role in health and biotechnology.

BASE: Benchmarking Agro-environmental database for Sustainable agriculture intensification
Building a BASE dataset enables robust predictions of yield potential, resource efficiency, and sustainability thresholds, driving climate resilience and sustainable agricultural intensification

ForestUNLOCK: A multi-modal Multiscale Benchmark Dataset for AI-Driven Boreal Forest Monitoring and Carbon Accounting
Building the first consistent multi-modal single tree benchmark for forest structure and carbon stock assessments of the northern boreal forest

GRIDMARK – Generating Reproducible Insights through Data Benchmarking for AI in Energy Systems
Transforming energy systems toward climate neutrality: Distribution grids have the potential to be catalysts for the energy transition. Unfortunately, most Distribution System Operators lack the resources to fully monitor their systems. Therefore, there is an urgent need for more high-quality data, particularly to develop and test machine learning models.
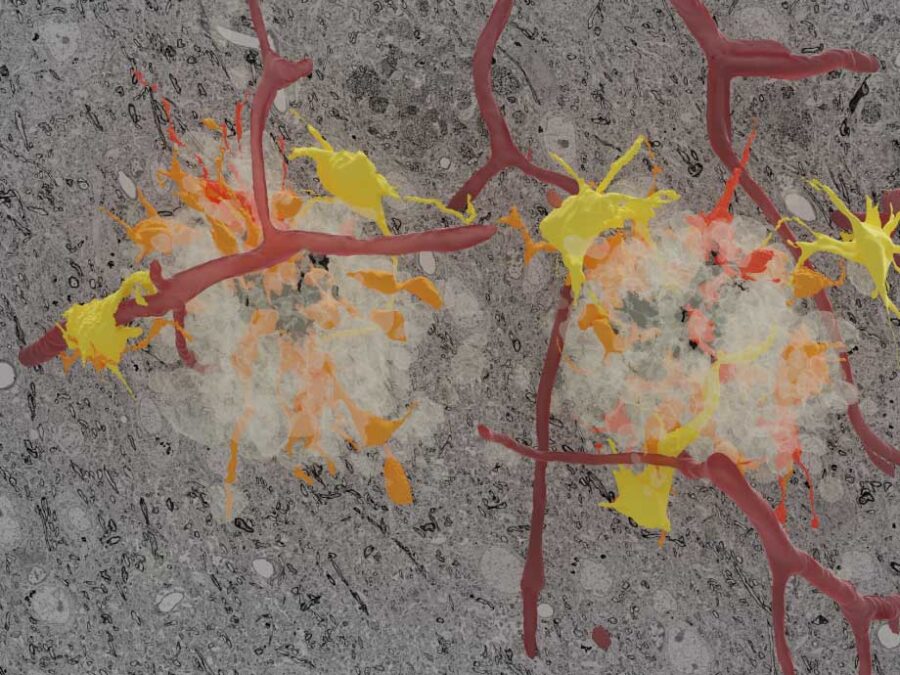
NeuroHarmonize – A Benchmark Decentralized Data Harmonization Workflow for AI-Driven Alzheimer’s Disease Management
The benchmark addresses the lack of harmonized, reproducible, and privacy-preserving multimodal datasets for Alzheimer’s disease (AD). NeuroHarmonize creates a FAIR-compliant, decentralized benchmarking framework to accelerate reliable, transparent, and collaborative AI for AD diagnosis, prognosis, and long-term monitoring.

Pero – Unlocking ML Potential: Benchmark Datasets on Perovskite Thin Film Processing
Addressing the lack of standardized, FAIR benchmark datasets in perovskite photovoltaics. Pero enables reproducible AI models for efficiency prediction, material classification, and defect detection, which are critical for industrial scaling of sustainable energy technologies.
RenewBench – A Global Benchmark for Renewable Energy Generation
Renewable energy’s variability makes grid management complex. RenewBench aims to provide standardized, high-quality data to advance trustworthy AI models and accelerate the transition to sustainable energy.
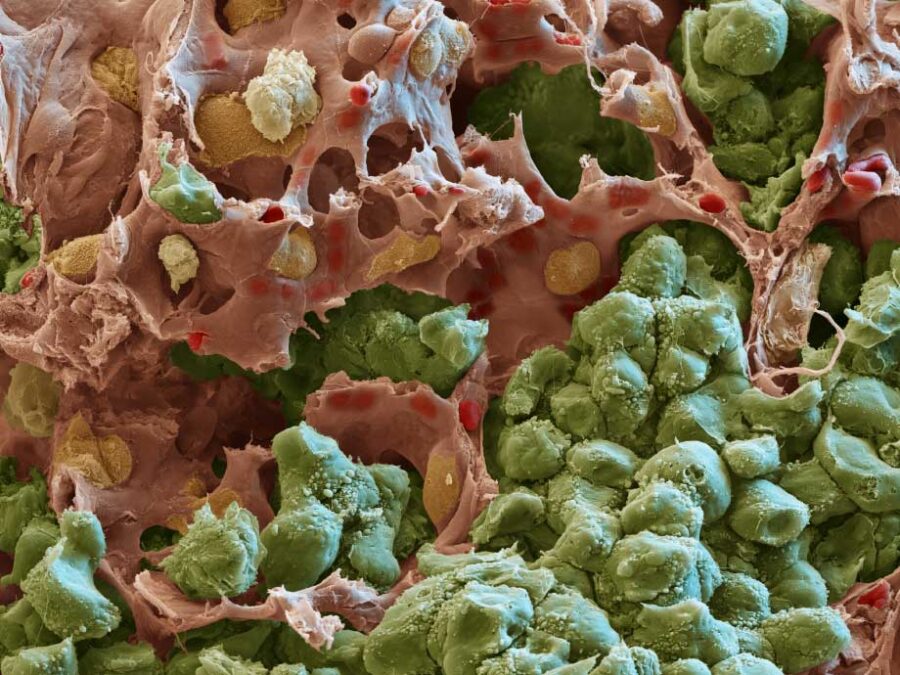
SCHEMA – profiling Spatial Cancer HEterogeneity across modalities to benchmark Metastasis risk prediction
SCHEMA creates a benchmark dataset linking tumor samples with metastasis outcomes to enable machine-learning models that predict metastasis risk and support clinical decision-making.
TIMELY: Time-series Integration across Modalities for Evaluation of Latent DYnamics
TIMELY provides the first comprehensive benchmark for multimodal biological time-series data, addressing the lack of standardized, high-quality datasets for modeling complex dynamical systems. It fosters the development of statistical and foundation models tailored to the analytical needs of research in biomedicine and neuroscience.

UQOB – Uncertainty Quantification in Object-detection Benchmark
Creating a benchmark dataset for object-detection and Uncertainty Quantification (UQ) in a multi-rater setting, to address annotation variability and AI model evaluation.